Various measurements and indicators are used in every company, in every organization. The choice of approaches to assessing the degree of achievement of a certain indicator (for example, a sales plan) is huge: there are so many people, companies, situations, types of work, so many opinions. The purpose of this article is not to invent anything of our own, but to try to classify the dominant majority of existing approaches to measuring indicators. In accordance with measurement theory, when modeling a real phenomenon, one must first establish the types of scales in which certain variables are measured or should be measured. What is a scale? What are they? What restrictions are placed on the numbers used for measurements? How to use scales correctly to obtain reliable primary measurements? What integral and complex indicators can be built on multiple measurements taken on different scales?
Scales and their classifications
Scales are used both for primary measurements and for converting different measurements (in our case, different indicators) into a single scale. How to choose a single scale? Let's start with three definitions.
A scale is a system of numbers or other elements and relationships between them, adopted for measuring or assessing any quantities (objects, qualities, etc.).
Scaling is:
- choice of scale for primary measurements;
- transferring a measurement from one scale to another.
Normalization (or uniform scaling) is the transfer of all variables and indicators that reflect different measurement objects into one scale.
The first classification of scales was proposed by S. Stevens in 1946 and is not fundamentally different from the modern generally accepted classification. Scales are usually grouped into three main groups:
- nominal - for qualitative measurements;
- ordinal - to reflect the relationship of order (more, better, more important, simpler, more correct, etc.);
- quantitative - they operate with numbers in the way we are used to from school (for example, 10 is 2 times more than 5).
Sometimes all measurement scales are divided into two classes:
- scales of qualitative characteristics (ordinal scale and name scale);
- scales of quantitative characteristics (quantitative scales).
Next, we will sequentially analyze all types of scales.
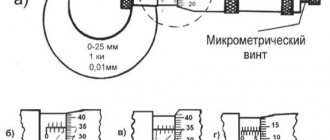
How to count points in the decathlon?
Today, in the men's track and field decathlon, a participant is awarded about 1,000 points for successful performance in each sport. But what result do you think counts as 1000? The first thing that comes to mind is to take the world record for women for 1000 points. But which one exactly? The current one is not suitable, since it changes, but I would like to be able to make comparisons over time and measure records. But let’s say we fix once and for all what 1000 points are awarded for: in the long jump, for example, in 7.90 m, in the 100-meter run - in 11 seconds. Then another question arises: which step should I specify? Is a score of 8.00 m in the long jump worth 1050 or 1010 points? And how can we fairly compare different types of competitions? It seems that each specialist will have his own opinion and his own scale on this matter.
Conclusion
Thus, it became clear what a measurement scale is and what it is used for. As it turns out, she is not alone. There are five of them, and each is used to measure certain quantities. If earlier it seemed that the scale should measure only physical quantities, then it turns out that sciences such as psychology and sociology also have their own scales that measure numerical indicators. In fact, a psychological test is also such a scale.
The quantity being measured is called a variable, and the thing with which the measurement is made is called an instrument. The result is data or results that can be of varying quality and belong to one of the scales. Each of them places restrictions on the use of certain mathematical operations.
Nominal scales
The nominal scale, or naming scale 1, compares each object with a specific characteristic. As a result, an object either has this characteristic or it does not. The nominal scale consists of names - this is the simplest and at the same time correct understanding of the nominal scale. Example. Red or black is a dimension in a certain color range. Many classifications and answers to questionnaires are all examples of nominal measurements. The work of the creators of the balanced scorecard begins with them, and it should end with numbers. But here it is important not to overdo it and leave nominal measurements only where they are preferable to formal digitization.
How to use scales correctly to obtain reliable primary measurements? This is not as simple a question as it seems at first glance.
Acceptable transformations. In the nominal scale, valid transformations (see sidebar) are all one-to-one transformations 2. For example, red is “red.” There are no relations other than “equal” and “unequal” here. In this scale, numbers are used only as marks (as, for example, when handing over laundry to the laundry), that is, only to distinguish objects.
Valid Conversions
Mathematicians strictly describe scales with this concept. The type of scale is specified by the group of its permissible transformations. Valid transformations are those that do not change the relationship between the objects of measurement and, accordingly, the conclusions drawn from the measurement results. For example, when measuring length, the transition from arshins to meters does not change the relationship between the lengths of the objects under consideration: if the first object is five times longer than the second times, then this will be established when measuring both in arshins and in meters. Please note that in this case the numerical value of the length in arshins differs from the length in meters - only the result of comparing the lengths of two objects does not change. Similarly, monetary amounts can be compared both in rubles and in foreign currency. A feature associated with changing exchange rates: the result of comparing amounts of money in different currencies changes over time. The situation with arshins and meters is different: their ratio is eternal. So much for the problem of exchange rate differences in the economy. This is not the place to talk about it now, but remember it.
Measurement and Product Quality
As mentioned earlier, if you successfully resolve issues related to the accuracy of measuring the quality parameters of materials and other products, as well as maintaining modes in production technology, product quality will significantly improve. In simple terms, quality control is the measurement of all parameters of technological processes. The results of their measurements are needed to control the process. The more accurate the results, the better the control.
The measurement state has the following basic properties:
- Reproducibility of measurement results.
- Accuracy.
- Convergence.
- Receipt speed.
- Unity of measurements.
Reproducibility of results is the closeness of measurement results of the same quantity, which were obtained in different places, using different methods and means, at different times and by different people, but under the same conditions (humidity, pressure, temperature).
Convergence of measurement results is when the results of measurements of the same quantity, which were carried out repeatedly using the same means, by the same method, under the same conditions, with the same care, are close.
Any measurement is carried out using appropriate scales.
Ordinal scales
The ordinal scale reflects a higher level of measurement, taking into account what category an object belongs to and what relationship it has with other objects. In an ordinal scale, numbers are used not only to differentiate objects, but also to establish order between them. Example. The simplest example of an ordinal scale is student assessments of knowledge. It is symbolic that in secondary school grades 2, 3, 4, 5 are used, and in higher school the same meaning is expressed verbally - “unsatisfactory”, “satisfactory”, “good”, “excellent”. This emphasizes the “non-numerical” nature of students’ knowledge assessments. In fact, measurement on an ordinal scale is an ordering operation. Comparisons of “more - less” or “better - worse” are assumed. For example, expert opinions are often expressed on an ordinal scale, that is, an expert may say (and justify) that one product quality indicator is more important than another; the first technological object is more dangerous than the second, etc. But he is not able to say how many times or how much more important it is, or, accordingly, more dangerous. Acceptable transformations. An ordinal scale allows any increasing transformation, that is, one that does not change the order of the scale. Types of ordinal scales. Two types of ordinal scales are used, which are different from a practical point of view:
- ranking scale, which involves assigning ranks to objects (ranking);
- point scale on which scores are applied.
Thinking about measuring some indicators should begin with a choice between rank and point types of scales.
Name scale
This scale is also called nominal. It is the simplest. Numbers play the role of labels in it. They are needed in order to detect and distinguish the objects being studied. The numbers that make up this scale can be swapped. There are no “less-more” relationships in it. For this reason, some people think that its application should not be taken as a measurement. Using a naming scale, only a small number of mathematical operations can be performed. For example, you cannot subtract and add its numbers, but you can count how many times a certain number appears.
Rank ordinal scales
Rank scales are scales where numbers serve only to assign places. Experts are often asked to rank (order) the objects of examination, that is, arrange them in increasing (or decreasing) order of intensity of the characteristic being studied. Rank is the number of the object of examination in an ordered series of characteristic values for various objects. Formally, ranks are expressed by the numbers 1, 2, 3…. It is important to remember that measurements 1, 2, 3 and 6, 10, 50 mean the same thing: the first alternative took first place, the second took second place, etc. Rank scales do not contain information about the magnitude of the differences between the objects being assessed. Such scales are used when an object is difficult to describe with several characteristics, which are then assessed qualitatively (by points, for example) or quantitatively. In management practice, ratings are often based on ranking scales.
Rank measurements (ranking procedures). There are several main types of ranking algorithms:
- direct ranking procedure , when the expert must simply order the objects. When ranking, he places objects in order of preference, guided by knowledge, his own considerations, etc. - in fact, he places objects in a certain order, using his own algorithm and without explaining why he chose this particular option;
- indirect ranking procedure , when the expert must order objects and give explanations;
- sequential direct ranking procedure , when the expert must first assign objects to one of several classes to which he has previously assigned ranks, and then order the objects within each class. The method is used when there are a large number of ranking objects;
- The "bubble method" is taken from programming, where it is used for sorting. The expert must find the place of the (N+1)th object in a series of already ordered N-objects. This procedure is very economical and accurate;
- The procedure for paired comparisons is that the expert establishes the order of objects by comparing all possible pairs of them. This is the most accurate, but also the most time-consuming method. Translating the results of such paired comparisons into ranks is not so simple; an example of incorrect translation of the results of paired comparisons into ranks is given in the sidebar.
The simplest (and incorrect) translation of the results of paired comparisons into ranks and weights
It is tempting to derive weights, that is, quantitative measures, from ordinal measurements. However, as a rule, such an action is incorrect - it is ambiguous and therefore a single and correct conclusion for management tasks is impossible. At the same time, it is popular, especially among people who do not know mathematics well. Let us give an example of the simplest and most popular modification of the paired comparison method. Let's say an expert evaluates four methods that are related to solving personnel issues in a corporate project: Z1 - advanced training during the project; Z2 - attracting external personnel; Z3 - personnel training at your corporate university; Z4 - one-time advanced training.
| Zi/Zj | Z1 | Z2 | Z3 | Z4 |
| Z1 | 1 | 1 | 1 | |
| Z2 | 0 | 0 | 0 | |
| Z3 | 0 | 1 | 1 | |
| Z4 | 0 | 1 | 0 |
Let’s create a matrix of binary expert preferences, where 1 means that one method is “preferred” than the other with which it is compared. Let's determine the evaluation of each method (add it by row): C1 = 3; C2 = 0; C3 = 2; C4 = 1. We get the order of preference for methods: Z1, Z3, Z4, Z2. So far these are all correct actions. Then comes the turn of “creativity”. The simplest (and incorrect) translation of pairwise comparison results into weighting coefficients. If you need “weights” of the indicated four alternatives, then you can normalize the numbers {C} and get the “weights” {v} by dividing each value of C by the sum of all CI, equal to six: v1 = 3/6 = 0.5; v2 = 0; v3 = 0.33; v4 = 0.17. Check: the sum of the weights must be equal to 1. However, the analysis of the correctness of the method gives a negative result. The fact is that objects can be assigned other weights (see a similar example below). Why is it incorrect? Because as a result of its applications, the weight of v1 turns out to be three times greater than v4, and the expert who conducted the pairwise comparison did not claim this! The falsification is obvious, since as a result of processing we added a significant amount of information from ourselves to what the experts said.
Correct methods for converting pairwise comparison results to an interval scale. They exist. Considering preference to be a random variable that reflects the true ratio of the characteristics of the objects of comparison, we can solve the problem of determining the probability of the true ratio of the objects being compared (models of Bradley-Terry, Thurstone-Mosteller, Lewis, etc.). An example of such a correct translation is given in the box. It does not have much practical significance, and to understand its essence, you need to have a good knowledge of mathematical statistics 3. But it is important to understand that such methods exist and they have a justification, albeit not controversial. As a result, the method of paired comparisons makes it possible to determine the significance of differences in the position of certain objects in the hierarchy, as well as solve other similar problems.
Correct translation of pairwise comparison results into an interval scale
During a survey of experts in August 2001, the quality of gasoline in four companies, Lukoil, Yukos and Tatneft, was compared in pairs. When comparing four companies, 6 pairs are obtained for comparison: Table 1. Comparison of companies by gasoline quality
| Couples | Frequency of selection of the first element of a pair | Frequency of selection of the second element of a pair |
| "TNK" - "Lukoil" | π(1,2) = 0.508 | π(2,1) = 0.492 |
| "TNK" - "Yukos" | π(1.3) = 0.331 | π(3,1) = 0.669 |
| "TNK" - "Tatneft" | π(1.4) = 0.990 | π(4,1) = 0.010 |
| Lukoil - Yukos | π(2,3) = 0.338 | π(3,2) = 0.662 |
| "Lukoil" - "Tatneft" | π(2.4) = 0.990 | π(4,2) = 0.010 |
| Yukos - Tatneft | π(3.4) = 0.997 | π(4.3) = 0.003 |
Based on the results of paired comparisons, it was possible to express the “gasoline quality” V1, V2, V3, V4 on an interval scale (see below). It is easy to notice that the “values” V1, V2, V3, V4 are measured on an interval scale. The origin of coordinates can be chosen arbitrarily, since the probabilities of the comparison results depend only on the pairwise differences of “values” V1, V2, V3, V4. For example, let us assume that V4 = 0. For the assessment, we used the Thurstone-Mosteller model, according to which the errors of expert opinions are independent, normally distributed random variables with zero mathematical expectation and variance σ2. Since the variance of the difference of our conditional random variables V1, V2, V3, V4 is equal to 2σ2, it is convenient to choose the unit of measurement so that 2σ2 = 1. As a result, we obtain the following values: V1("TNK") = V2("Lukoil") = 2, 326348, V3(Yukos) = 2.747781, V4(Tatneft) = 0. Thus, Yukos has the highest quality gasoline; TNK and Lukoil, which are identical in this indicator, are somewhat worse, and Tatneft is significantly worse than the top three.
Measurement scales. Types of scales
⇐ PreviousPage 3 of 16Next ⇒Measurement scales
In practical activities, it is necessary to carry out measurements of various quantities that characterize the properties of bodies, substances, phenomena and processes. As was shown in the previous sections, some properties appear only qualitatively, others - quantitatively. Various manifestations (quantitative or qualitative) of any property form sets, the mappings of whose elements onto an ordered set of numbers or, in a more general case, conventional signs form measurement scales
these properties.
The quantitative property measurement scale is the PV scale. A physical quantity scale
is an ordered sequence of PV values, adopted by agreement based on the results of precise measurements. The terms and definitions of the theory of measurement scales are set out in document MI 2365-96.
In accordance with the logical structure of the manifestation of properties, five main types of measurement scales are distinguished.
1. Naming scale (classification scale).
Such scales are used to classify empirical objects whose properties appear only in relation to equivalence. These properties cannot be considered physical quantities, therefore scales of this type are not PV scales. This is the simplest type of scale, based on assigning numbers to the qualitative properties of objects, playing the role of names.
In naming scales in which the assignment of a reflected property to a particular equivalence class is carried out using human senses, the most adequate result is the one chosen by the majority of experts. In this case, the correct choice of classes of the equivalent scale is of great importance - they must be reliably distinguished by observers and experts assessing this property. The numbering of objects on a scale of names is carried out according to the principle: “do not assign the same number to different objects.” Numbers assigned to objects can be used to determine the probability or frequency of occurrence of a given object, but they cannot be used for summation or other mathematical operations.
Since these scales are characterized only by equivalence relations, they do not contain the concepts of zero, “more” or “less” and units of measurement. An example of naming scales are widely used color atlases designed for color identification.
2. Order scale (rank scale).
If the property of a given empirical object manifests itself in relation to equivalence and order in increasing or decreasing quantitative manifestation of the property, then an order scale can be constructed for it. It is monotonically increasing or decreasing and allows you to establish a greater/lesser ratio between quantities characterizing the specified property. In order scales, zero exists or does not exist, but in principle it is impossible to introduce units of measurement, since a proportionality relation has not been established for them and, accordingly, there is no way to judge how many times more or less specific manifestations of a property are.
In cases where the level of knowledge of a phenomenon does not allow one to accurately establish the relationships that exist between the values of a given characteristic, or the use of a scale is convenient and sufficient for practice, conditional (empirical) order scales are used. Conditional scale
is a PV scale, the initial values of which are expressed in conventional units. For example, the Engler viscosity scale, the 12-point Beaufort scale for sea wind strength.
Order scales with reference points marked on them have become widespread. Such scales, for example, include the Mohs scale for determining the hardness of minerals, which contains 10 reference (reference) minerals with different hardness numbers: talc - 1; gypsum - 2; calcium - 3; fluorite - 4; apatite - 5; orthoclase - 6; quartz - 7; topaz - 8; corundum - 9; diamond - 10. The assignment of a mineral to a particular gradation of hardness is carried out on the basis of an experiment, which consists of scratching the test material with a supporting one. If after scratching the tested mineral with quartz (7) a trace remains on it, but after orthoclase (6) there is no trace, then the hardness of the tested material is more than 6, but less than 7. - It is impossible to give a more accurate answer in this case.
In conventional scales, the same intervals between the sizes of a given quantity do not correspond to the same dimensions of the numbers displaying the sizes. Using these numbers you can find probabilities, modes, medians, quantiles, but they cannot be used for summation, multiplication and other mathematical operations.
Determining the value of quantities using order scales cannot be considered a measurement, since units of measurement cannot be entered on these scales. The operation of assigning a number to a required value should be considered an estimation.
Assessment on order scales is ambiguous and very conditional, as evidenced by the example considered.
3. Interval scale (difference scale).
These scales are a further development of order scales and are used for objects whose properties satisfy the relations of equivalence, order and additivity. The interval scale consists of identical intervals, has a unit of measurement and an arbitrarily chosen beginning - the zero point. Such scales include chronology according to various calendars, in which either the creation of the world, or the Nativity of Christ, etc. is taken as the starting point. The Celsius, Fahrenheit and Reaumur temperature scales are also interval scales.
The interval scale defines the actions of adding and subtracting intervals. Indeed, on a time scale, intervals can be summed or subtracted and compared by how many times one interval is greater than another, but adding up the dates of any events is simply pointless.
The Q interval scale is described by the equation
where q is the numerical value of the quantity; — the beginning of the scale; — unit of the quantity under consideration. Such a scale is completely determined by specifying the origin of the scale and the unit of a given value.
There are practically two ways to set the scale. In the first of them, two values and quantities are selected that are relatively simply implemented physically. These values are called reference points,
or
main reference points,
and the interval ( ) is
the main interval.
The point is taken as the origin, and the value is taken as the unit Q. In this case, n is chosen such that it is an integer value.
The conversion of one interval scale to another is carried out according to the formula
(2.2)
The numerical value of the interval between the starting points on the scales under consideration, measured in degrees Fahrenheit ( , is equal to 32. The transition from temperature on the Fahrenheit scale to temperature on the Celsius scale is made according to the formula.
In the second way of specifying the scale, the unit is reproduced directly as an interval, a certain fraction of it, or a certain number of intervals of the size of a given value, and the starting point is chosen differently each time depending on the specific conditions of the phenomenon being studied. An example of this approach is a time scale in which 1 s = 9,192,631,770 periods of radiation corresponding to the transition between two hyperfine levels of the ground state of the cesium-133 atom. The beginning of the phenomenon under study is taken as the reference point.
4. Relationship scale.
These scales describe the properties of empirical objects that satisfy the relations of equivalence, order and additivity (scales of the second kind are additive), and in some cases proportionality (scales of the first kind are proportional). Their examples are the scale of mass (second kind), thermodynamic temperature (first kind).
In ratio scales, there is an unambiguous natural criterion for the zero quantitative manifestation of a property and a unit of measurement established by agreement. From a formal point of view, the ratio scale is an interval scale with a natural origin. All arithmetic operations are applicable to the values obtained on this scale, which is important when measuring EF.
Relationship scales are the most advanced. They are described by the equation Q = q[Q], where Q is the PV for which the scale is constructed, [Q] is its unit of measurement, q is the numerical value of the PV. The transition from one scale of relations to another occurs in accordance with the equation.
5. Absolute scales.
Some authors [22,23] use the concept of absolute scales, which are understood as scales that have all the features of ratio scales, but additionally have a natural unambiguous definition of the unit of measurement and do not depend on the adopted system of units of measurement. Such scales correspond to relative values: gain, attenuation, etc. To form many derived units in the SI system, dimensionless and counting units of absolute scales are used.
Note that scales of names and order are called non-metric (conceptual),
and the scales of intervals and ratios are
metric (material).
Absolute and metric scales belong to the category of linear. The practical implementation of measurement scales is carried out by standardizing both the scales and units of measurement themselves, and, if necessary, the methods and conditions for their unambiguous
Types and methods of measurements
Types and methods of measurements.
Measurements as experimental procedures for determining the values of measured quantities are very diverse, which is explained by the multitude of measured quantities, the different nature of their changes over time, different requirements and accuracy of measurements, etc.
Measurements, depending on the method of processing experimental data to find the result, are classified as direct, indirect, joint and cumulative.
Direct measurement is a measurement in which the desired value of a quantity is found directly from experimental data as a result of the measurement.
(Example: measuring source voltage with a voltmeter).
Indirect measurement is a measurement in which the desired value of a quantity is found on the basis of a known relationship between this quantity and the quantities subjected to direct measurements.
(For example: the resistance of a resistor R is found from the equation R=U/I, into which the measured values of the voltage drop U across the resistor and the current I through it are substituted).
Joint measurements are simultaneous changes in several different quantities to find the relationship between them. In this case, a system of equations is solved.
(For example: determine the dependence of the resistor resistance on temperature Rt = R0(1+At+Bt2); by measuring the resistance of the resistor at three different temperatures, they create a system of three equations, from which the parameters R0, A and B of the dependence are found).
Cumulative measurements are simultaneous measurements of several quantities of the same name, in which the desired values of the quantities are found by solving a system of equations made up of the results of direct measurements of various combinations of these quantities. (For example: measuring the resistance of resistors connected in a triangle by measuring the resistance between different vertices of the triangle; the results of three measurements determine the resistance of the resistors).
The interaction of measuring instruments with an object is based on physical phenomena, the totality of which constitutes the measurement principle, and the set of techniques for using the principle and measuring instruments is called the measurement method .
The numerical value of the measured quantity is obtained by comparing it with a known quantity reproduced by a certain type of measuring instrument - a measure.
Depending on the method of applying a measure of a known quantity, a distinction is made between the method of direct assessment and methods of comparison with the measure.
In the direct assessment method, the value of the measured quantity is determined directly from the reading device of a direct conversion measuring device, the scale of which was previously calibrated using a multi-valued measure that reproduces the known values of the measured quantity.
(Example: measuring current using an ammeter).
Methods of comparison with a measure - methods in which a comparison is made of the measured value and the value of the reproducible measure.
Comparison can be direct or indirect through other quantities that are uniquely related to the first.
A distinctive feature of comparison methods is the direct participation in the measurement process of a measure of a known quantity that is homogeneous with the one being measured.
The group of comparison methods with a measure includes the following methods: zero , differential , substitution and coincidence .
With the zero measurement method, the difference between the measured quantity and the known quantity or the difference between the effects produced by the measured and known quantities is reduced to zero during the measurement process, which is recorded by a highly sensitive device - a null indicator.
With high accuracy of measures reproducing a known value and high sensitivity of the null indicator, high measurement accuracy can be achieved.
(Example: measuring the resistance of a resistor using a four-arm bridge, in which the voltage drop across a resistor of unknown resistance is balanced by the voltage drop across a resistor of known resistance.)
With the differential method, the difference between the measured value and the value of a known, reproducible measure is measured using a measuring device.
The unknown quantity is determined from the known quantity and the measured difference. In this case, the balancing of the measured value with a known value is not carried out completely, and this is the difference between the differential method and the zero method. The differential method can also provide high measurement accuracy if the known value is reproduced with high accuracy and the difference between it and the unknown value is small.
Example: Measuring DC voltage Ux using a discrete voltage divider R U and a voltmeter V
Fig.1.1. Voltage measurement circuit using the differential method.
Unknown voltage Ux=U0+ Ux, where U0 is the known voltage, Ux is the measured voltage difference.
With the substitution method, the measured quantity and a known quantity are alternately connected to the input of the device, and the value of the unknown quantity is estimated from the two readings of the device. The highest measurement accuracy is obtained when, as a result of selecting a known value, the device produces the same output signal as with an unknown value.
Example: measuring a small voltage using a highly sensitive galvanometer, to which a source of unknown voltage is first connected and the pointer deflection is determined, and then the same pointer deflection is obtained using an adjustable source of known voltage. In this case, the known voltage is equal to the known one.
With the coincidence method, the difference between the measured value and the value reproduced by the measure is measured using the coincidence of scale marks or periodic signals.
Example: measuring the rotation speed of a part using a flashing strobe lamp: observing the position of the mark on the rotating part when the lamp flashes, but the frequency of the flashes and the displacement of the mark determine the rotation speed of the part.
Measurement error. Basic concepts and types of errors
. Basic concepts and types of errors.
The measurement procedure consists of the following main steps:
—accepted models of the measurement object;
—choice of measurement method;
—selection of measuring instruments;
—conducting an experiment to obtain a numerical value of a measurement result.
Various shortcomings inherent in these stages lead to the fact that the measurement result differs from the true value of the measured value.
The reasons for the error may vary.
Measuring transformations are carried out using various physical phenomena, on the basis of which it is possible to establish the relationship between the measured quantity of the object of study and the output signal of the measuring instrument, by which the measurement result is evaluated.
It is never possible to accurately establish this relationship due to insufficient knowledge of the object of study and the inadequacy of its adopted model, the impossibility of accurately taking into account the influence of external factors, insufficient development of the theory of physical phenomena underlying the measurement, the use of simple but approximate analytical dependencies instead of more accurate but complex and etc.
The concept of “error” is one of the central ones in metrology, where the concepts of “error of the measurement result” and “error of the measuring instrument” are used. Measurement result error
is the difference between the measurement result X and the true (or actual) value Q of the measured quantity:
It indicates the limits of uncertainty in the value of the measured quantity. Measuring instrument error
— the difference between the SI reading and the true (actual) value of the measured EF. It characterizes the accuracy of the measurement results carried out by this tool.
These two concepts are in many ways close to each other and are classified according to the same criteria.
By nature of manifestation
errors are divided into random, systematic, progressive and gross (misses).
Note that from the above definition of error it does not in any way follow that it must consist of any components. The division of the error into components was introduced for the convenience of processing measurement results based on the nature of their manifestation. During the formation of metrology, it was discovered that the error is not a constant value. Through elementary analysis, it was established that one part of it appears as a constant value, while the other changes unpredictably. These parts were called systematic and random errors.
As will be shown in Sect. 4.3, the change in error over time is a non-stationary random process. Dividing the error into systematic, progressive and random components is an attempt to describe different parts of the frequency spectrum of this broadband process: infra-low-frequency, low-frequency and high-frequency.
Random error
- a component of the measurement error that changes randomly (in sign and value) in a series of repeated measurements of the same EF size, carried out with the same care under the same conditions. There is no pattern observed in the appearance of such errors (Fig. 4.1); they are detected during repeated measurements of the same quantity in the form of some scatter in the results obtained. Random errors are inevitable, irremovable and always present as a result of measurement. Description of random errors is possible only on the basis of the theory of random processes and mathematical statistics.
Unlike systematic, random errors cannot be eliminated from measurement results by introducing a correction, but they can be significantly reduced by increasing the number of observations. Therefore, to obtain a result that differs minimally from the true value of the measured value, multiple measurements of the required value are carried out, followed by mathematical processing of the experimental data.
Of great importance is the study of random error as a function of observation number i or the corresponding time point 1 of the measurements, i.e. D; = A(t.). Individual error values are values of the function A(t), therefore, the measurement error is a random function of time. When carrying out multiple measurements, one realization of such a function is obtained. This is exactly the implementation shown in Fig. 4.1. Repeating a series of measurements will give us another implementation of this function, different from the first, etc. The error corresponding to each i-th measurement is the cross section of the random function A(t). In each section of this function one can find the average value around which the errors in various implementations are grouped. If a smooth curve is drawn through the average values obtained in this way, it will characterize the general trend of changes in the error over time.
Systematic error
— component of the measurement error that remains constant or changes naturally with repeated measurements of the same PV. Constant and variable systematic errors are shown in Fig. 4.2. Their distinctive feature is that they can be predicted, detected and, thanks to this, almost completely eliminated by introducing an appropriate correction.
It should be noted that recently the above definition of systematic error has been subject to justified criticism, especially in connection with technical measurements. It is quite reasonably proposed [7, 58] to consider systematic error as a specific, “degenerate” random variable (see Section 5.1), which has some, but not all, properties of a random variable studied in probability theory and mathematical statistics. Its properties, which must be taken into account when combining error components, are reflected by the same characteristics as the properties of “real” random variables: dispersion (standard deviation) and cross-correlation coefficient.
Progressive (drift) error
is an unpredictable error that changes slowly over time. This concept was first introduced in the monograph by M.F. Malikov “Fundamentals of Metrology” [17], published in 1949. Distinctive features of progressive errors:
• they can be corrected by amendments only at a given point in time, and then change unpredictably again;
• changes in progressive errors over time are a nonstationary random process, and therefore, within the framework of a well-developed theory of stationary random processes, they can be described only with certain reservations.
The concept of progressive error is widely used in studying the dynamics of SI errors [5] and the metrological reliability of the latter.
Gross error (miss)
- this is a random error in the result of an individual observation included in a series of measurements, which, for given conditions, differs sharply from the other results of this series. They usually arise due to errors or incorrect actions of the operator (his psychophysiological state, incorrect readings, errors in records or calculations, incorrect switching on of devices or malfunctions in their operation, etc.). Short-term sudden changes in measurement conditions can also be a possible cause of errors. If errors are detected during the measurement process, the results containing them are discarded. However, most often errors are identified only during the final processing of measurement results using special criteria, which are discussed in Chapter. 7.
According to the way of expression ,
distinguish between absolute, relative and reduced errors.
Absolute error
is described by formula (4.1) and is expressed in units of the measured quantity.
However, it cannot fully serve as an indicator of measurement accuracy, since the same value, for example, D = 0.05 mm at X = 100 mm corresponds to a fairly high measurement accuracy, and at X = 1 mm - low. Therefore, the concept of relative error is introduced. Relative error
is the ratio of the absolute measurement error to the true value of the measured quantity:
This visual characteristic of the accuracy of the measurement result is not suitable for normalizing the SI error, since when the values change, Q takes on different values up to infinity at Q = 0. In this regard, to indicate and normalize the SI error, another type of error is used - reduced.
The given error is
this is a relative error in which the absolute error of the SI is related to the conventionally accepted one, constant over the entire measurement range or part of it:
The conventionally accepted value QN is called normalizing.
Most often, the upper limit of measurements of a given SI is taken as it, in relation to which the concept of “reduced error” is mainly used.
Depending on the place of origin
distinguish between instrumental, methodological and subjective errors.
Instrumental error
due to the error of the used SI.
Sometimes this error is called hardware error.
Methodological error
measurements are determined by:
• the difference between the accepted model of the measured object and the model that adequately describes its property, which is determined by measurement;
• influence of methods of using SI. This occurs, for example, when measuring voltage with a voltmeter with a finite value of internal resistance. In this case, the voltmeter shunts the section of the circuit on which the voltage is measured, and it turns out to be less than it was before connecting the voltmeter;
• the influence of algorithms (formulas) by which measurement results are calculated;
• the influence of other factors not related to the properties of the measuring instruments used.
A distinctive feature of methodological errors is that they cannot be indicated in the regulatory and technical documentation for the measuring instrument used, since they do not depend on it, but must be determined by the operator in each specific case. In this regard, the operator must clearly distinguish between the quantity actually measured and the quantity to be measured.
Subjective (personal) error
measurements are due to the operator’s error in reading readings on SI scales and diagrams of recording instruments. They are caused by the condition of the operator, his position during work, imperfection of the sensory organs, and the ergonomic properties of the SI. The characteristics of personal error are determined on the basis of the normalized nominal value of the scale division of the measuring instrument (or the chart paper of the recording instrument), taking into account the ability of the “average operator” to interpolate within the scale division.
According to the dependence of the absolute error on the values of the measured quantity
errors are distinguished (Fig. 4.4):
• additive
, independent of the measured value;
• multiplicative
, which are directly proportional to the measured value;
• nonlinear
, having a nonlinear dependence on the measured value.
These errors are used mainly to describe the metrological characteristics of SI. The division of errors into additive, multiplicative and nonlinear is very important when addressing the issue of normalization and mathematical description of SI errors.
Examples of additive errors are from a constant load on a scale, from inaccurate zeroing of the instrument needle before measurement, from thermo-EMF in direct current circuits. The causes of multiplicative errors can be: a change in the gain of the amplifier, a change in the rigidity of the pressure gauge sensor membrane or the device spring, a change in the reference voltage in a digital voltmeter.
Rice. (1).4. Additive (a), multiplicative (b) and nonlinear (c) errors
According to the influence of external conditions
distinguish between main and additional SI errors.
The main
error is the SI error, determined under normal conditions of its use.
For each measuring instrument, the operating conditions are specified in the regulatory and technical documents - a set of influencing quantities (ambient temperature, humidity, pressure, voltage and frequency of the supply network, etc.) under which its error is normalized. Additional
is the SI error that arises due to the deviation of any of the influencing quantities.
Depending on the influence of the nature of the change in the measured quantities
SI errors are divided into static and dynamic.
Static error
is the error of the SI used to measure PV, taken as constant.
Dynamic
is the error of the SI, which additionally arises when measuring the variable PV and is caused by the discrepancy between its response to the rate (frequency) of change of the measured signal.
⇐ Previous3Next ⇒
What makes your dreams come true? One hundred percent, unshakable confidence in your...
What does the IS operation and maintenance department do? Responsible for the safety of data (copying schedules, copying, etc.)…
WHAT HAPPENS WHEN WE FIGHT Without understanding the differences that exist between men and women, it is very easy to lead to a quarrel...
Conflicts in family life. How can I change this? It is rare that a marriage and relationship exists without conflict and tension. Everyone goes through this...
Didn't find what you were looking for? Use Google search on the site:
Point ordinal scales
Point scales are used very often; we have already given examples.
However, it is important to understand that each score must be assigned a qualitative characteristic, otherwise correctness may suffer. Let me give you an example: in the late 1990s. I was appointed the responsible teacher (quality, control, appeals) at the oral exam in economics for applicants to the National Research University Higher School of Economics. The rector's office has just introduced a 10-point scale. The impromptu attempt was unsuccessful - the first pancake, as usual, came out lumpy. My job included, among other things, “ensuring fairness,” that is, so that teachers in different commissions would give the same points for approximately the same answers. The range of ratings turned out to be terrifying - from 4 to 7 for similar answers. Literally the next day, the error in the definition of the scale was corrected, and the resulting scale (see Table 2) still works successfully (with a slight change). Many universities have adopted it. I draw the attention of readers that in accordance with the specifics of each subject, the teacher specifies the scale. Table 2. Example of a 10-point scale for assessing student performance.
| Point | Qualitative characteristics |
| 10 | A+ - exceptional knowledge (even the teacher didn’t know some of the student’s answer) |
| 9 | Excellent, solid A |
| 8 | Five minus |
| 7 | Four plus |
| 6 | Four, solid four |
| 5 | Four minus |
| 4 | Three plus |
| 3 | Three, a solid rating of “satisfactory” |
| 2 | Three minus |
| 1 | Unsatisfactory |
An important question: what is the ideal dimension of a scoring scale? Answer: as many qualities as there are points. The scores represent ordered qualities, and each quality is assigned a different score. The opposite is not true: if you take a 10-point scale as a basis and try to “assign” a certain quality to each point, you may encounter a situation where there may not be 10 qualities, but only 7. Therefore, you should start from the number of qualities that you can identify .
If there is no justification for the logic of assigning points, we will consider the measurement incorrect. This is necessary for correct scoring.
Point measurements. Point measurements are formally simple, but are insidious with the possibility of allowing unreasonable assessments and thereby ruining everything. There are two approaches to scoring:
- direct scoring is the assignment of points to objects based on subjective perception. Such an assessment is used in sociology, but should not be used in company management (except, perhaps, at the initial stage of developing a system of indicators). The reason is simple - points are assigned to objects too arbitrarily, it is difficult to explain why we put 5 on a 10-point scale, and not 6, for example;
- scoring with justification is a procedure for assigning points to objects based on the degree of closeness to the qualities described by the points. In my opinion, this is necessary for correct scoring. Let's accept the following rule: if there is no justification for the logic of assigning points, we will consider the measurement incorrect .
Translation of scoring results into weighting coefficients. If such a translation is done by one expert, this is a dubious, but popular operation. The sidebar shows one of the popular methods - the method of sequential comparisons .
Conversion of ranks into weighting coefficients by one expert. Sequential comparison method
Let's continue the example given in the sidebar. So, the expert assesses four goals related to solving the personnel problem. The options are ranked as follows: Z1, Z3, Z4, Z2. Step 1. All assessed objects are arranged in descending order of their importance. Preliminary importance scores are assigned, the sum of which differs from 100. In this case, the first object in the array receives a score of 100, the rest - in accordance with their importance. We give preliminary estimates (conditional points): p1 = 100, p3 = 60, p4 = 40, p2 = 10. Step 2. The first object of the array is compared with all possible combinations of lower-level objects, and in each combination two such objects are taken. It is believed that the combination can be considered as a sum, that is, both objects are “realized.” If necessary, the assessment of the first object is adjusted. Let's compare goals and adjust their estimates: compare Z1 with (Z3 and Z4) (that is, compare goal Z1 with a combination of Z3 and Z4), then compare Z1 with (Z3 and Z2) and so on. Let's say the expert believes that Z1 is better than Z3 and Z4 combined, but Z3+Z4 total 100 conditional points, so we adjust the assessment: p1 = 125. Step 3. The second object of the array is compared with all possible combinations of lower-level objects, and in each combination, again only two such objects are taken. If necessary, the assessment of the second object is adjusted, etc. For example, Z3 is compared with (Z4 and Z2). The remaining comparisons do not bring anything new. Step 4. The adjusted estimates are normalized and the object weights are calculated based on them. Let's write down the adjusted estimates and calculate the weights of the goals: p1 = 125; p3 = 60; p4 = 40; p2 = 10; v1 = 125/sum of all ratings = 0.54; v3 = 0.25; v4 = 0.17; v2 = 0.04. Now these weights can be used in the additive utility function 4. You will evaluate the correctness of the calculations later, after becoming familiar with quantitative scales and the estimates obtained based on measurements in them.
Quantitative scales
Quantitative scales reflect a higher level of measurement, taking into account not only the relationship of the measured object to other objects, but also the degree of their difference. We see examples of the use of quantitative scales everywhere. Acceptable transformations. Quantitative scales are defined up to transformations that do not change the units of measurement (linear or other functional transformations). Types of quantitative scales. There are quantitative scales:
- intervals;
- degrees;
- relationships;
- differences;
- absolute scale.
The location of the scales in this list is not accidental. The first (interval scale) is the weakest in terms of information content and the strongest in terms of reliability of estimates, the last (absolute scale) is the most informative (measurements can be very reliable), but at the same time allowing for the least reliable estimates. Assessing the degree of compliance with some ideal is extremely difficult - remember the difference between assessment and measurement? An interval scale (interval scale) precisely determines the amount of interval between points on a scale. To carry out measurements, you must set an interval (2 points). Acceptable transformations in the interval scale are linear increasing transformations of the form: F(X) = a · X + b, where a > 0.
The scale is power. The power scale (power) allows a power transformation (F(X) = AXB). In the field of technology, it is quite adequate - it also has two degrees of freedom, like an interval scale. In economics, on the contrary, it is an exception, so we will not consider it in detail.
The interval scale is the weakest in terms of information content and gives the most reliable estimates. The absolute scale is the most informative, but allows for the least reliable assessments. Assessing the degree of compliance with some ideal on an absolute scale is extremely difficult - remember the difference between assessment and measurement?
Relationship scale. Of the quantitative scales in science and practice, the most common are ratio scales. They have a natural reference point - zero (that is, the absence of a value), but there is no natural unit of measurement. Examples of using the ratio scale:
- measurement of most physical units: body weight, length, and prices in economics;
- any percentage is a measurement on a ratio scale;
- simple indices such as Current Year's Revenue/Last Year's Revenue also represent a measurement on a ratio scale.
The ratio scale allows transformations that change only the scale, that is, similarity transformations: F(X) = aX, where a > 0 (linear increasing transformations without a free term). Examples of ratio scale transformations:
- conversion of prices from one currency to another at a fixed rate;
- converting weight from kilograms to pounds.
The base point in the scale of relationships is one - “one”. This conventional “unit” can be, for example, 100 (percent) or 1 (share). Thus, measurements in shares and percentages are equivalent, which is obvious even without any theory. However, conclusions drawn from percentage measurements can be misleading (see box). Related questions arise:
- Do similar comparisons occur in management practice?
- What percentages can be compared with each other and why?
- What actions can be performed with interest?
- what actions can be performed with indexes?
Correctness of percentage measurements. Putin's rating vs the cost of pork
- Putin's rating: in January 2014 - 60.6%, in June 2014 - 87.4%.
- Pork price: in January - 116 rubles/kg, in June - 195 rubles/kg.
Conclusion: in terms of growth rates (in the scientific terminology of “growth”), pork beats Putin: 44% vs 68%.
Are these measurements correct? Decide for yourself and explain (which is much more difficult). Only 10% of MBA students are able to accurately formulate how correct such comparisons are. This is another argument in favor of studying scales. At least at the level of acquaintance. The difference scale allows for a shift transformation: F(X) = X + b. In such a scale there is a natural unit of measurement, but there is no natural reference point. The base point in the scale of differences is also the same - the conventional “zero”, a kind of reference point. Example: time is measured on a difference scale if the natural unit of measurement is taken to be a year (or a day - from noon to noon). At the current level of knowledge, it is impossible to indicate a natural starting point. Even the date of creation of the world is calculated differently by different authors, as well as the date of birth of Jesus Christ. An absolute scale is a scale that prohibits transformations 5. Only for an absolute scale are measurement results (numbers) used in the usual sense as numerical values. An example of measurements on an absolute scale is the number of employees of a company or revenue. At the same time, the estimate of revenue may differ from the revenue itself (for example, 20 million rubles is “good”, 24.5 million rubles is “excellent”). In addition to the six main types of quantitative scales listed, other scales are sometimes used.
Degrees of freedom of scales
To carry out measurements on ratio and difference scales, we must specify one point. In the scale of relations, it “plays the role of a unit,” that is, it corresponds to the translation of the basic empirical element into the unit of the real axis. For the difference scale, this is the “zero point,” that is, you need to set the ratio in such a way that the “reference point” of the empirical system turns into a numerical zero. In this regard, mathematicians distinguish scales according to degrees of freedom:
- 2 degrees of freedom have scales of intervals, degrees;
- 1st degree - scales of ratios and differences;
- 0 degrees is an absolute scale.
Absolute scale
Often the magnitude of something is measured directly. For example, they directly calculate the number of defects in products, the number of units produced, the number of students present at the lecture, how many years have been lived, and so on. By making such measurements, the exact absolute quantitative values of what is being measured are marked on the scale. The absolute value scale has exactly the same properties as the ratio scale. The only difference is that those quantities indicated on the first one are absolute, not relative.
The results obtained after measurement on this scale have the greatest reliability and information content. They are very sensitive to measurement inaccuracies.